Non-Autoregressive Open-Source TTS Models Review
Wed Jun 12 2024 • Andrey Paznyak
Read the Full Series of ML TTS exploration
- Part 1: Intro, Little Theory and Math 📘
- Part 2: Autoregressive models world 🌍
- Part 3: Non-autoregressive models hideout 🕵️♂️
- Part 4: Autoregressive and hybrid models review 📊
- 👉Part 5: Non-Autoregressive models review📝
- Part 6: DelightfulTTS implementation and training 🛠️
Non AR models

Typical NAR model
In the following sections, I will review the most interesting implementations and key ideas in the field of non-autoregressive (NAR) text-to-speech models. It’s important to note that not all models have published research papers or open-source code available. However, I will endeavor to uncover and present the relevant information and insights from the available sources.
FastPitch: Parallel Text-to-Speech with Pitch Prediction
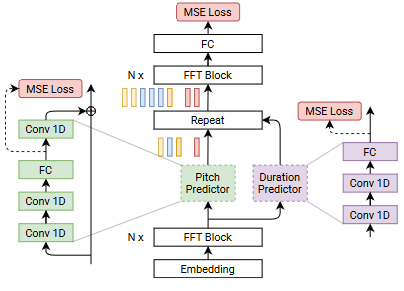
Implementation NVIDIA/NeMo: FastPitch and Mixer-TTS Training Traditional autoregressive TTS models, which generate speech one step at a time, suffer from slow inference speeds, making them unsuitable for real-time applications. FastPitch, proposed by NVIDIA in 2020, is a fully-parallel text-to-speech model that addresses these challenges by introducing parallel pitch prediction and conditioning the mel-spectrogram generation on the predicted pitch contours.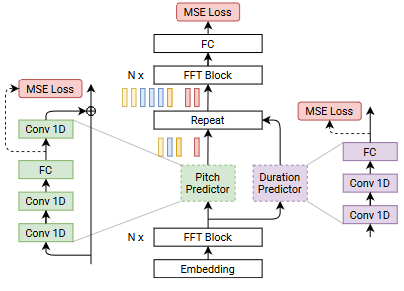
FastPeech schema
It is based on FastSpeech and composed mainly of two feed-forward Transformer (FFTr) stacks. The first one operates in the resolution of input tokens, the second one in the resolution of the output frames.
Key Contributions Parallel Pitch Prediction: One of the main innovations of FastPitch is its ability to predict the fundamental frequency (F0) contours, which represent the pitch variations in speech, directly from the input text in a fully-parallel manner. Unlike previous TTS models that predicted pitch contours autoregressively, FastPitch employs a feed-forward architecture (FFTr) and a dedicated pitch predictor to generate the pitch contours in a single pass. This parallel pitch prediction eliminates the need for autoregressive processing, leading to faster inference times. Conditioning on Pitch Contours: FastPitch conditions the mel-spectrogram generation, which represents the spectral characteristics of speech, on the predicted pitch contours. By explicitly modeling and incorporating the pitch information, FastPitch can capture and reproduce the natural variations in pitch and intonation present in human speech, resulting in more natural-sounding synthesized audio. Feed-Forward Architecture: FastPitch is a feed-forward model, which means that it does not rely on recurrent neural networks (RNNs) or attention mechanisms. This architecture choice contributes to the model’s efficiency and parallelizability. Improved Speech Quality: By explicitly modeling pitch contours and conditioning the mel-spectrogram generation on them, FastPitch achieves improved speech quality compared to its predecessor, FastSpeech. The synthesized speech exhibits more natural-sounding pitch variations and intonation patterns. Limitations and Future Work While FastPitch represents a significant advancement in parallel text-to-speech synthesis, the authors acknowledge some limitations and suggest future research directions: Prosody Modeling: Although FastPitch improves pitch prediction, further work is needed to model other aspects of prosody, such as duration and energy contours, in a parallel and efficient manner. Multi-Speaker Adaptation: The FastPitch model presented in the paper is trained on a single-speaker dataset. Extending the model to handle multiple speakers and enable efficient speaker adaptation remains an open challenge. Deployment and Inference Optimization: While FastPitch offers faster inference times compared to autoregressive models, further optimization and deployment strategies could be explored to enable real-time applications and on-device inference. Overall, FastPitch is a notable contribution to the field of text-to-speech synthesis, introducing parallel pitch prediction and demonstrating improved speech quality while maintaining computational efficiency. However, there is still room for further research and development to address the remaining limitations and expand the model’s capabilities.
DelightfulTTS: The Microsoft Speech Synthesis System for Blizzard Challenge 2021
DelightfulTTS is a text-to-speech (TTS) system developed by Microsoft for the Blizzard Challenge 2021, a prestigious annual evaluation of TTS systems. This system aims to generate high-quality and expressive speech while maintaining computational efficiency. Architecture DelightfulTTS is based on a non-autoregressive (NAR) architecture, which allows for parallel generation of mel-spectrograms, enabling faster inference compared to traditional autoregressive models. The acoustic model still faces the challenge of the one-to-many mapping problem, where multiple speech variations can correspond to the same input text. To address this issue, DelightfulTTS systematically models variation information from both explicit and implicit perspectives:
- For explicit factors like speaker ID and language ID, lookup embeddings are used during training and inference.
- For explicit factors like pitch and duration, the values are extracted from paired text-speech data during training, and dedicated predictors are employed to estimate these values during inference.
- For implicit factors like utterance-level and phoneme-level prosody, reference encoders are used to extract the corresponding values during training, while separate predictors are employed to predict these values during inference.
The acoustic model in DelightfulTTS is built upon non-autoregressive generation models like FastSpeech, incorporating an improved Conformer module to better capture local and global dependencies in the mel-spectrogram representation. By explicitly modeling variation information from multiple perspectives and leveraging non-autoregressive architectures, DelightfulTTS aims to generate high-quality and expressive speech while addressing the one-to-many mapping challenge inherent in text-to-speech synthesis. Schema: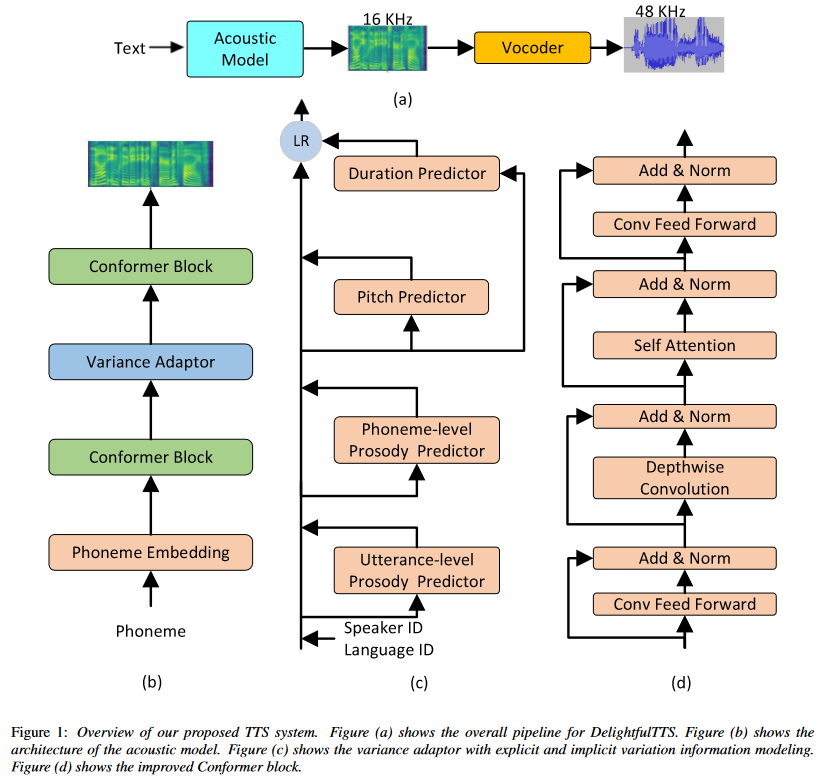
Conformer Architecture The Conformer architecture is a variant of the Transformer model that integrates both convolutional neural networks (CNNs) and self-attention mechanisms. It was originally proposed for end-to-end speech recognition tasks and later adopted for TTS systems due to its ability to capture both local and global dependencies in the input sequences. In the context of TTS, the Conformer architecture is typically used in the acoustic model, which is responsible for generating the mel-spectrogram representation of speech from the input text. Mathematically, the Conformer block can be represented as follows: Let X be the input sequence. The key components of the Conformer block used in the acoustic model are:
- Convolutional Feed-Forward Module: This module applies a 1D convolutional layer to the input sequence, capturing local dependencies.
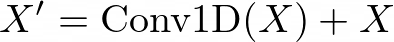
- Depthwise Convolution Module: This module applies a depthwise 1D convolutional layer, further enhancing the modeling of local correlations.
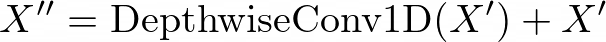
- Self-Attention Module: This module employs multi-headed self-attention, allowing the model to capture global dependencies and long-range interactions within the input sequence.
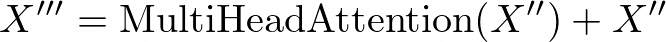
- Second Convolutional Feed-Forward Module: Another convolutional feed-forward module is applied after the self-attention module, further processing the output.
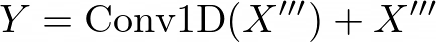
Here, Conv1D, DepthwiseConv1D, and MultiHeadAttention represent the convolutional, depthwise convolutional, and multi-headed self-attention operations, respectively. The Conformer architecture combines the strengths of CNNs and self-attention, allowing the model to capture both local and global dependencies in the input sequence. This is particularly important for TTS tasks, where the model needs to generate mel-spectrograms of varying lengths while capturing the prosodic and acoustic characteristics of speech. In the DelightfulTTS model, the authors likely employed the Conformer architecture in the acoustic model to benefit from its ability to model both local and global dependencies, leading to improved prosody and audio fidelity in the synthesized speech. Variation Information Modeling Text-to-speech (TTS) is a typical one-to-many mapping problem where there could be multiple varying speech outputs (e.g., different pitch, duration, speaker, prosody, emotion, etc.) for a given text input. It is critical to model these variation information in speech to improve the expressiveness and fidelity of synthesized speech. While previous works have tried different methods to model the information, they focus on a specific aspect and cannot model in a comprehensive and systematic way. In this paper, considering that different variation information can be complementary to each other, the authors propose a unified way to model them in the proposed variance adaptor (as shown in Figure 1c). Categorization of Variation Information Observing that some variation information can be obtained implicitly (e.g., pitch can be extracted by some tools) or explicitly (e.g., utterance-level prosody can only be learned by the model), the authors categorize all the information they model as follows:
- Explicit Modeling: Language ID, Speaker ID, Pitch, Duration
- Implicit Modeling: Utterance-level prosody, Phoneme-level prosody
For speaker and language ID, lookup embeddings are used in training and inference. For pitch and duration, the values are extracted from paired text-speech data in training, and two predictors are used to predict the values in inference. For utterance-level and phoneme-level prosody, two reference encoders are used to extract the values in training , and two separate predictors are used to predict the values in inference. The two reference encoders are both made up of convolution and RNN layers. Utterance-level prosody vector is obtained by the last RNN hidden and a style token layer. Phoneme-level prosody vectors are obtained by using the outputs of the phoneme encoder (phoneme-level) as a query to attend to the outputs of the mel-spectrogram reference encoder (frame-level). Different from, the authors do not use VAE but directly use the latent representation as the phoneme-level vector for training stability . The utterance-level prosody predictor contains a GRU layer followed by a bottleneck module to predict the prosody vector. The phoneme-level prosody predictor takes both the outputs of the text encoder and the utterance-level prosody vector as input. With the help of the utterance-level prosody vector, the authors do not need an autoregressive prosody predictor as in for faster inference. By unifying explicit and implicit information in different granularities (language-level, speaker-level, utterance-level, phoneme-level) in the variance adaptor, the authors aim to achieve better expressiveness in prosody and controllability in pitch and duration. Key Contributions
- Non-Autoregressive Architecture: DelightfulTTS employs a non-autoregressive architecture, enabling faster inference compared to autoregressive models while maintaining high speech quality.
- Explicit Prosody Modeling: The system explicitly models pitch and energy contours, in addition to duration, to capture the prosodic variations in speech, leading to more natural and expressive synthesized speech.
- Multi-Speaker Capabilities: DelightfulTTS supports multi-speaker synthesis by conditioning the generation process on speaker embeddings, enabling efficient speaker adaptation.
Limitations and Future Work While DelightfulTTS represents a significant advancement in non-autoregressive TTS, the authors acknowledge some limitations and suggest future research directions:
- Robustness to Long Inputs: The system’s performance may degrade for very long input sequences, and further work is needed to improve robustness and consistency for such cases.
- Fine-Grained Prosody Control: While DelightfulTTS models pitch, energy, and duration, additional work could explore more fine-grained control over prosodic aspects, such as emphasis and phrasing.
- Deployment and Optimization: Further optimization and deployment strategies could be explored to enable real-time applications and on-device inference, leveraging the non-autoregressive architecture’s potential for efficiency.
Overall, DelightfulTTS is a notable contribution to the field of text-to-speech synthesis, demonstrating the potential of non-autoregressive architectures and explicit prosody modeling for generating high-quality and expressive speech. The system’s performance in the Blizzard Challenge 2021 highlights its competitiveness and the progress made in this domain.
AR and non-AR TTS Models Review Summary
Based on my research, I haven’t found a clear convergence between the areas of autoregressive (AR) and non-autoregressive (NAR) text-to-speech models in terms of combining or composing them into a single unified model. The key requirements for NAR models are sustainability, the ability to guarantee stability in the generated audio sequences, balanced quality, and fast generation speed, which is a significant advantage of the NAR architecture. Both the FastPitch and DelightfulTTS models meet these criteria. However, I prefer the DelightfulTTS model because it is more complex compared to FastPitch and can potentially provide more diverse results. The DelightfulTTS model’s complexity and diversity could be further enhanced by incorporating ideas from the StyledTTS2 model, which uses diffusion as an AR variator to make the speech more unique and expressive based on the context. While the diffusion-based approach in StyledTTS2 can introduce expressiveness, the NAR nature of DelightfulTTS can contribute to the stability of the generated speech. Therefore, a potential direction could be to explore a hybrid approach that combines the strengths of DelightfulTTS’s NAR architecture with the expressive capabilities of the diffusion-based variator from StyledTTS2. Such a hybrid model could leverage the stability and efficiency of the NAR framework while incorporating the contextual expressiveness and diversity offered by the diffusion-based variator. However, it’s important to note that integrating these two approaches into a single unified model may pose challenges, and further research is needed to investigate the feasibility and effectiveness of such a hybrid approach. This brings us to the next article…
Next chapter
Part 6: DelightfulTTS implementation and training 🛠️ Author: Nick Ovchinnikov
Original article: https://medium.com/@peechapp/text-to-speech-models-part-5-non-autoregressive-models-review-7ce8de9c9e9d
Level up your reading with Peech
Boost your productivity and absorb knowledge faster than ever.
Start now