Tweaking, Implementing and Training DelightfulTTS Model
Wed Jun 12 2024 • Andrey Paznyak

Read the Full Series of ML TTS exploration
- Part 1: Intro, Little Theory and Math 📘
- Part 2: Autoregressive models world 🌍
- Part 3: Non-autoregressive models hideout 🕵️♂️
- Part 4: Autoregressive and hybrid models review 📊
- Part 5: Non-autoregressive models review📝
- 👉Part 6: DelightfulTTS implementation and training 🛠️
Everything we are covering in this article can be found in 🔗TTS-Peech github repo. The repository serves as a comprehensive resource where you can explore the implementation details, review the documentation, and examine the test cases that ensure the code’s reliability and correctness. You can find all the documentation inside the docs directory, run the docs locally with mkdocs serve. Also here you can take a look on the docs online.
Intro
On the way to building state-of-the-art text-to-speech and after conducting research, I decided to implement the DelightfulTTS model. I didn’t find many details in the paper about the implementation and hyperparameters, but I found the Comprehensive-Transformer-TTS repository and was heavily influenced by this implementation. For example, you can check the Conformer implementation: Comprehensive-Transformer-TTS/model/transformers/conformer.py I also found another great implementation on GitHub: dunky11/voicesmith
VoiceSmith makes it possible to train and infer on both single and multispeaker models without any coding experience. It fine-tunes a pretty solid text to speech pipeline based on a modified version of DelightfulTTS and UnivNet on your dataset.
And there’s also a coqui-ai PR Delightful-TTS implemetation.
Pulp Friction
I chose to use my own training code due to the flexibility it offers in the training process. While PyTorch Lightning is an excellent training framework that simplifies multi-GPU training and incorporates many best practices, custom implementations come with their own set of advantages and disadvantages.
How to Train Our Model

Using PyTorch Lightning to train a model is very straightforward. My training script allows you to train on a single machine with either one or multiple GPUs. I tried to support the hyperparameters and configurations in one place. You can find the configuration in the models/config directory. PreprocessingConfig is the basic piece of configuration where you can set the configuration for preprocessing audio used for training. PreprocessingConfigUnivNet and PreprocessingConfigHifiGAN have different n_mel_channels, and these two configurations are not compatible because this parameter fundamentally defines the architecture of the AcousticModel. For the PreprocessingConfigHifiGAN , we have sampling rates of 22050 or 44100. You can see the post-initialization action that sets the parameters of stft based on this parameter:
To set up the cluster, you need to define the following environment variables:
You can also choose the logs directory and checkpoints paths:
Here’s my Trainer code. I use the DDPStrategy because it’s the only strategy that works in my case. Other useful parameters are:
Import the preprocessing configuration that you want to train and choose the type of training. For example: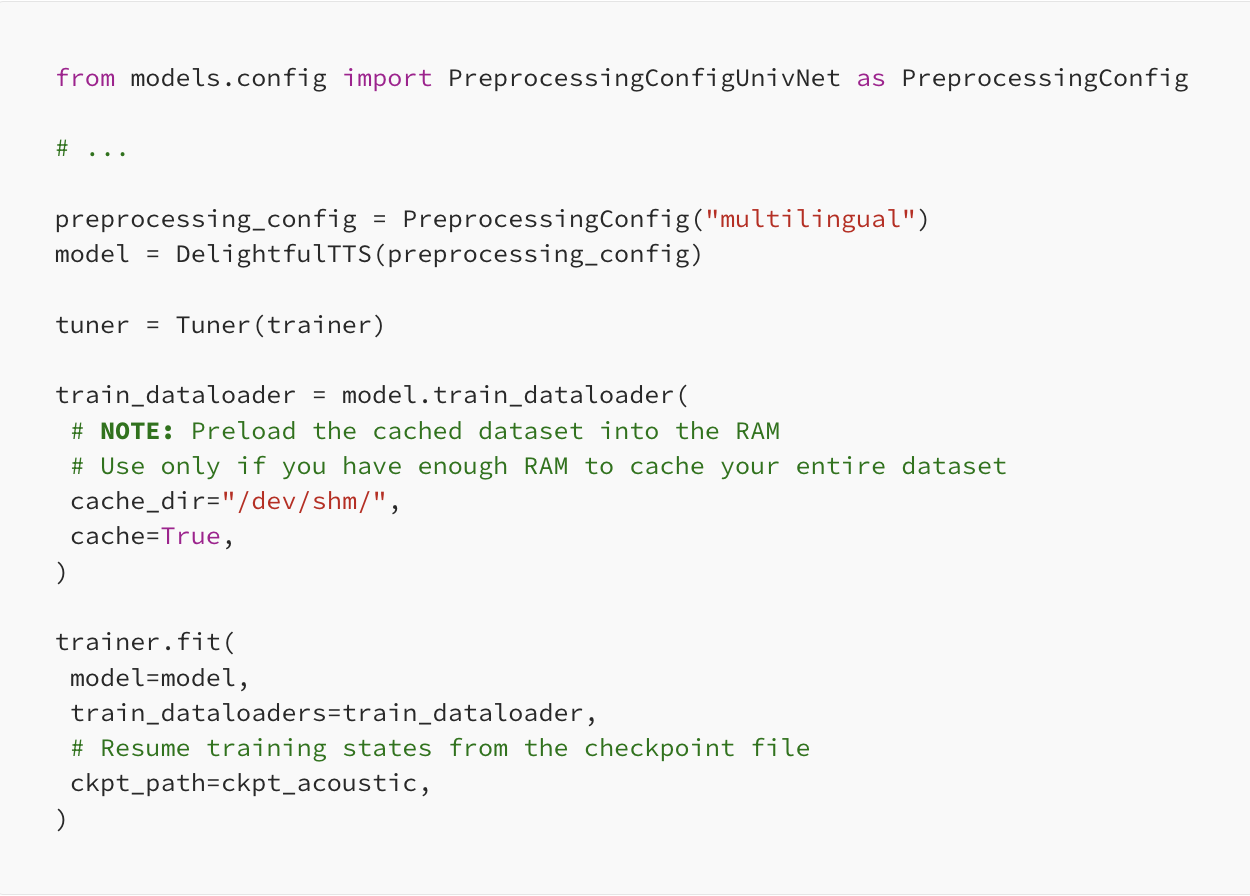
The entry point to the project is inside the train.py file, which serves as the foundation of the training process.
Inference code
For inference, you can use the code examples from demo/demo.py. You have three possible options for combining the acoustic model and vocoder:
- DelightfulTTS + UnivNet, with a sample rate of 22050 Hz
- DelightfulTTS + HiFi-GAN, with a sample rate of 44100 Hz
- FastPitch + HiFi-GAN, with a sample rate of 44100 Hz
You can experiment with these TTS models and find the best fit for your use case.
Dataset code
For managing datasets, I utilize the lhotse library. This library allows you to wrap your audio dataset, prepare cutset files, and then filter or select specific subsets of the data. For example:
With lhotse, you can filter your dataset based on various criteria, such as speaker identities or audio duration. Notably, you don’t need to read the audio metadata for this step, as the metadata is already present in the cutset file, which can be prepared beforehand. The lhotse library provides a wide range of functions and utilities for managing and processing speech datasets efficiently. I highly recommend exploring its capabilities to streamline your dataset preparation and filtering tasks. I have prepared the following ready-to-use datasets:
- HifiLibriDataset: This dataset code combines the Hi-Fi Multi-Speaker English TTS Dataset and LibriTTS-R. You can choose specific speakers from these datasets or filter the audio based on various parameters. The dataset code can cache data to the filesystem or RAM if needed. This dataset can be used to train the DelightfulTTS model.
- HifiGanDataset: This dataset code is designed for the HiFi-GAN model. The data is prepared in a specific way, as you can see in the __getitem__ method. With this dataset implementation, you can train the HiFi-GAN vocoder.
- LIBRITTS_R: This code is a modified version of the Pytorch LIBRITTS dataset.
Additionally, you can explore the dataset code I prepared for various experiments within this project.
Acoustic model
The acoustic model is responsible for generating mel-spectrograms from input phoneme sequences, speaker identities, and language identities. The core of your acoustic model is the AcousticModel class, which inherits from PyTorch’s nn.Module. This class contains several sub-modules and components that work together to generate the mel-spectrogram output. Encoder: The encoder is a Conformer module that processes the input phoneme sequences. It takes the phoneme embeddings, speaker embeddings, language embeddings, and positional encodings as input and generates a hidden representation. Prosody Modeling:
- Utterance-Level Prosody: The model includes an UtteranceLevelProsodyEncoder and a PhonemeProsodyPredictor (for utterance-level prosody) to capture and predict the prosodic features at the utterance level.
- Phoneme-Level Prosody: Similarly, there is a PhonemeLevelProsodyEncoder and a PhonemeProsodyPredictor (for phoneme-level prosody) to model the prosodic features at the phoneme level.
Variance Adaptor:
- Pitch Adaptor: The PitchAdaptorConv module is responsible for adding pitch embeddings to the encoder output, based on the predicted or target pitch values.
- Energy Adaptor: The EnergyAdaptor module adds energy embeddings to the encoder output, based on the predicted or target energy values.
- Length Adaptor: The LengthAdaptor module upsamples the encoder output to match the length of the target mel-spectrogram, using the predicted or target duration values.
Decoder: The decoder is another Conformer module that takes the output from the variance adaptor modules and generates the final mel-spectrogram prediction. Embeddings: The model includes learnable embeddings for phonemes, speakers, and languages, which are combined and used as input to the encoder. Aligner: The Aligner module is used during training to compute the attention logits and alignments between the encoder output and the target mel-spectrogram. The forward_train method defines the forward pass during training, where it takes the input phoneme sequences, speaker identities, language identities, mel-spectrograms, pitches, energies, and attention priors (if available). It computes the mel-spectrogram prediction, as well as the predicted pitch, energy, and duration values, which are used for computing the training loss. The forward method defines the forward pass during inference, where it takes the input phoneme sequences, speaker identities, language identities, and duration control value, and generates the mel-spectrogram prediction. Additionally, there are methods for freezing and unfreezing the model parameters, as well as preparing the model for export by removing unnecessary components (e.g., prosody encoders) that are not needed during inference. Implementation follows the DelightfulTTS architecture and incorporates various components for modeling prosody, pitch, energy, and duration, while leveraging the Conformer modules for the encoder and decoder.
Results
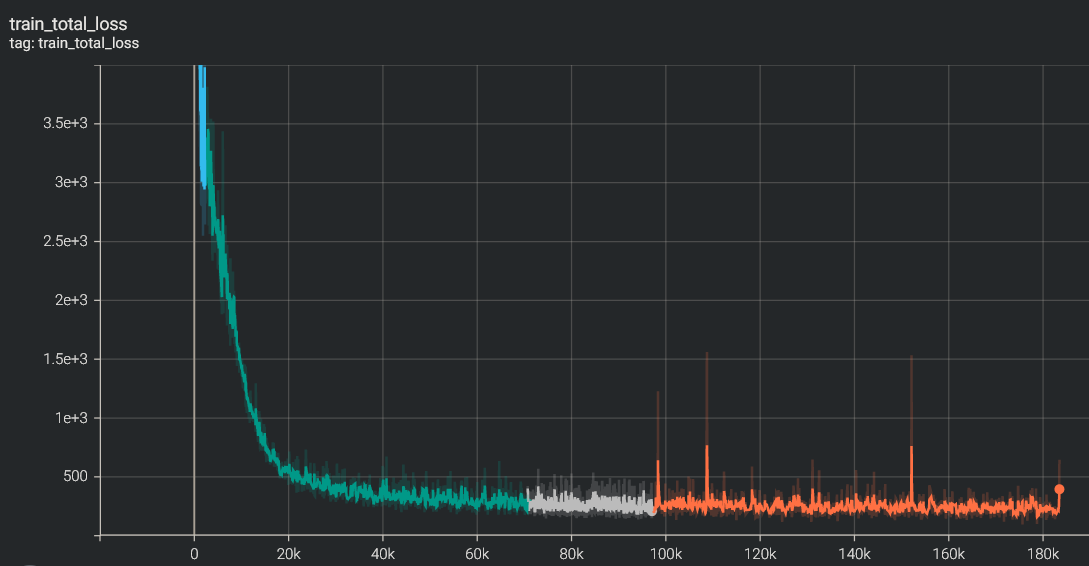
total loss
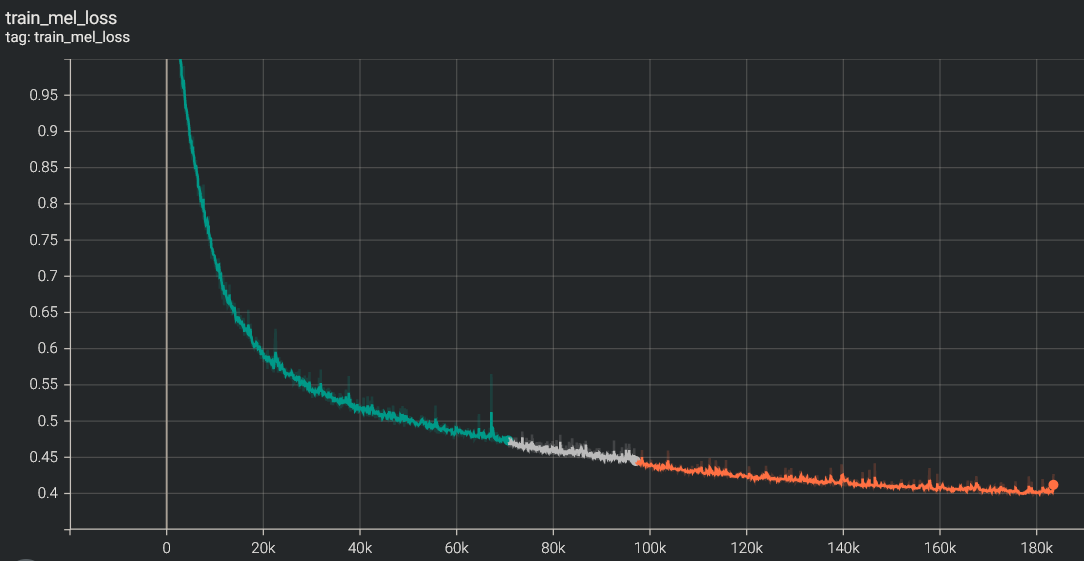
mel loss
Check the results:
Training the DelightfulTTS model is a computationally intensive task due to its large size and numerous components. Achieving stable and consistent results requires significant computational resources and time. In my experience, using 8 Nvidia V100 GPUs resulted in extremely slow progress, with visible improvements taking weeks to manifest. However, upgrading to 8 Nvidia A100 GPUs significantly accelerated the training process, allowing visible progress to be observed within days. For optimal performance and efficiency, the ideal hardware configuration would be a cluster with 16 Nvidia A100 GPUs. The computational demands of the DelightfulTTS model highlight the importance of leveraging state-of-the-art hardware accelerators, such as the Nvidia A100 GPUs, to enable practical training times and facilitate the development of high-quality text-to-speech systems.
Future work
The combination of autoregressive (AR) and non-autoregressive (NAR) architectures is a promising direction in the text-to-speech (TTS) field. Diffusion models can introduce sufficient variation, and the approach taken by StyledTTS2 is particularly appealing. A potential avenue for future exploration could be to integrate the FastPitch model, known for its speed and stability, with the diffusion block from StyledTTS2. This hybrid approach could leverage the strengths of both models. The NAR nature of FastPitch would contribute to the overall speed and stability of the system, while the diffusion-based component from StyledTTS2 could introduce diversity and expressiveness to the generated speech. By combining the efficient and robust FastPitch model with the expressive capabilities of the diffusion-based variator from StyledTTS2, this hybrid architecture could potentially deliver diverse and natural-sounding speech while maintaining computational efficiency and stability. However, integrating these two distinct approaches into a unified model may pose challenges, and further research would be necessary to investigate the feasibility and effectiveness of such a hybrid solution.
Thank you!
Author: Nick Ovchinnikov
Fin
Original article: https://medium.com/@peechapp/text-to-speech-models-part-6-delightfultts-implementation-and-training-ceb4c94fd5fb
Level up your reading with Peech
Boost your productivity and absorb knowledge faster than ever.
Start now