Non-Autoregressive Models Hideout
Wed Jun 12 2024 • Andrey Paznyak
Read the Full Series of ML TTS exploration
- Part 1: Intro, Little Theory and Math 📘
- Part 2: Autoregressive models world 🌍
- 👉Part 3: Non-autoregressive models hideout 🕵️♂️
- Part 4: Autoregressive and hybrid models review 📊
- Part 5: Non-autoregressive models review📝
- Part 6: DelightfulTTS implementation and training 🛠️
Non-autoregressive models (NAR)

Non-autoregressive (NAR) sequence generation is an alternative approach to autoregressive (AR) models, where the entire output sequence is generated in parallel, without relying on previously generated tokens. Unlike AR models, which generate the sequence one token at a time in an autoregressive manner, NAR models do not have any sequential dependencies during the generation process. The key advantage of NAR models is their computational efficiency and speed. By generating the entire sequence in a single pass, NAR models can significantly reduce the inference time compared to AR models, which can be particularly beneficial for applications that require real-time or low-latency performance.
Time Complexity Analysis
The time complexity of NAR models is constant, denoted as O(1), as the generation of the entire sequence is performed in a single pass, regardless of the sequence length. This is in contrast to AR models, which have a linear time complexity or O(n).
Definition

Note that in a non-autoregressive model, the probability of each token is independent of the previous tokens, in contrast to AR models, which model the conditional probabilities using the chain rule.
NAR model schema
Note: over-oversimplified schema, shouldn’t be considered seriously at all. Shows that every token is independent.
Dummy NAR schema
Cons of NAR models

NAR models generate each token independently, without considering the context of the previous tokens, models do not capture sequential dependencies between tokens, which can result in generated sequences that do not follow the natural flow of language. The independence assumption in the output space ignores the real dependency between target tokens. NAR models are not well-suited to capture hierarchical structures in language, such as syntax and semantics. Based on the nature NAR models may generate repetitive phonemes or sounds, leading to a lack of naturalness and coherence in the synthesized speech, models may generate shorter or broken utterances, failing to capture the full meaning or context of the input text. NAR models may generate speech that sounds unnatural or robotic, indicating a lack of understanding of the acoustic properties of speech, and also may struggle to capture long-range dependencies between tokens, leading to a lack of coherence and fluency in the generated sequence.
Text-to-Speech Non-Autoregressive models
Despite their limitations, Non-Autoregressive (NAR) models are still widely used in Text-to-Speech (TTS) systems. One of the main advantages of NAR models is their ability to generate speech much faster than Autoregressive (AR) models, thanks to their reduced computational requirements. This makes them well-suited for real-time TTS applications where speed is crucial. While NAR models may not produce speech that is as natural-sounding as AR models, they can still generate high-quality speech that is sufficient for many use cases.
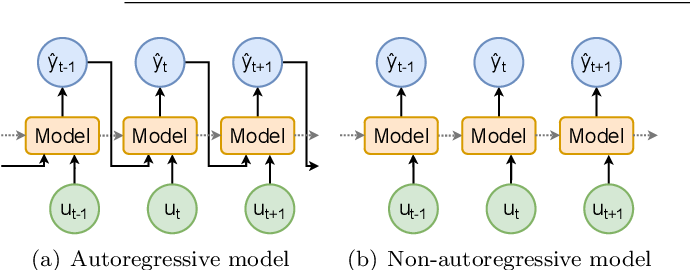
Side-by-side AR / NAR
To enhance the quality of the synthesized audio in non-autoregressive (NAR) text-to-speech models, researchers have explored the idea of incorporating additional modules or blocks to predict various speech parameters. By explicitly modeling speech parameters, such as pitch, energy, and other prosodic features, the models can generate more expressive and natural-sounding speech. For instance, in the FastPitch model, a dedicated pitch predictor module is introduced to generate pitch contours in parallel, which are then used to condition the mel-spectrogram generation. Schema of FastSpeech: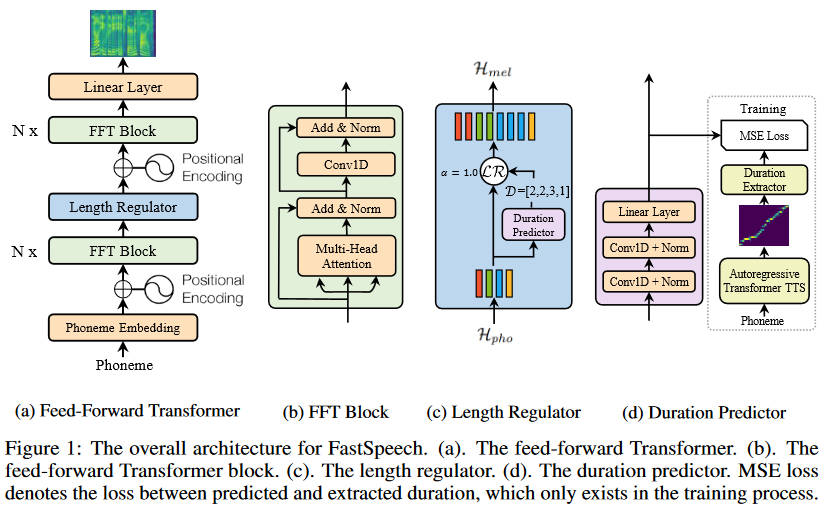
While introducing additional modules and conditioning the generation process on various speech parameters can improve the quality of the synthesized audio, it is important to strike a balance between model complexity and computational efficiency. The non-autoregressive nature of these models is designed to achieve faster inference speeds compared to autoregressive models, and adding too many complex modules or dependencies could potentially negate this advantage.
Next chapter
Part 4: Autoregressive and hybrid models review 📊 Author: Nick Ovchinnikov
Original article: https://medium.com/@peechapp/text-to-speech-models-part-3-non-autoregressive-models-hideout-f45e46a4f4bd
Level up your reading with Peech
Boost your productivity and absorb knowledge faster than ever.
Start now