Machine Learning Text-To-Speech: Intro, Little Theory and Math
Tue Jun 11 2024 • Andrey Paznyak
Read the Full Series of ML TTS exploration
- 👉Part 1: Intro, Little Theory and Math 📘
- Part 2: Autoregressive models world 🌍
- Part 3: Non-autoregressive models hideout 🕵️♂️
- Part 4: Autoregressive and hybrid models review 📊
- Part 5: Non-autoregressive models review📝
- Part 6: DelightfulTTS implementation and training 🛠️
Training Text-to-Speech Models: A Journey from Zero to…
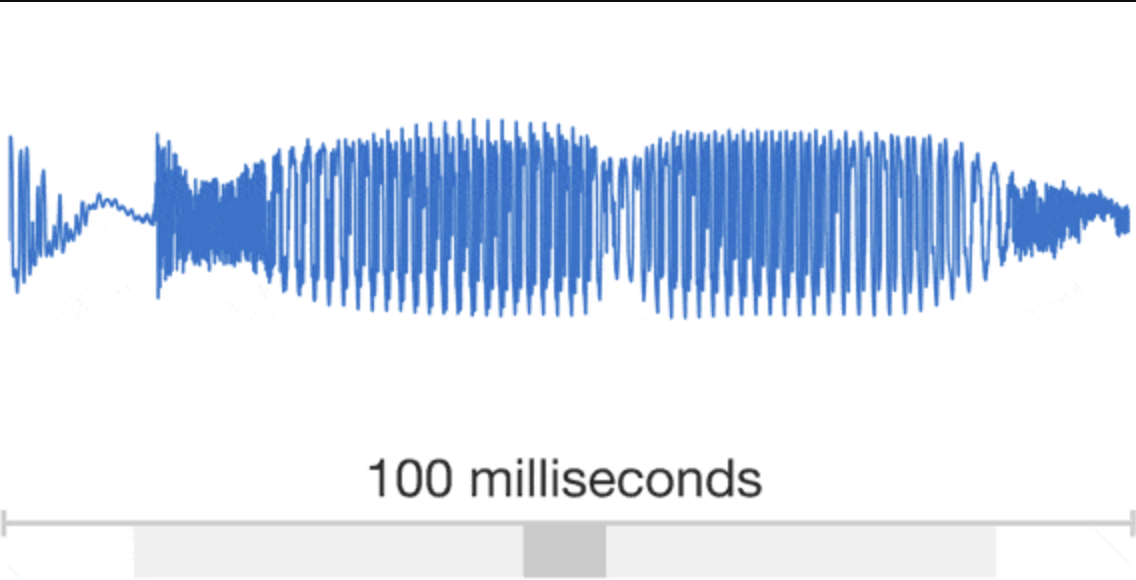
Developing a high-quality text-to-speech (TTS) system is a complex task that requires extensive training of machine learning models. While successful TTS models can revolutionize how we interact with technology, enabling natural-sounding speech synthesis for various applications, the path to achieving such models is often paved with challenges and setbacks. Training a TTS model from scratch is a challenging process that involves numerous steps, from data preparation and preprocessing to model architecture selection, hyperparameter tuning, and iterative refinement. Even with state-of-the-art techniques and powerful computational resources, it’s not uncommon for initial training attempts to fall short of expectations, yielding suboptimal results or encountering convergence issues. Audio is a very complicated data structure, just take a look for a 1 sec waveform…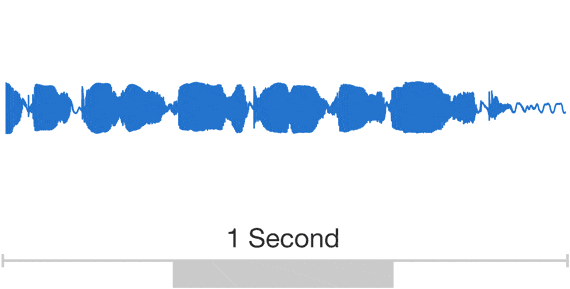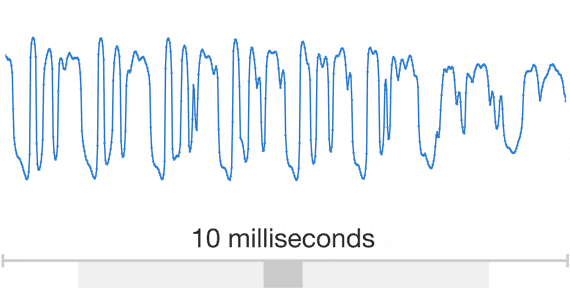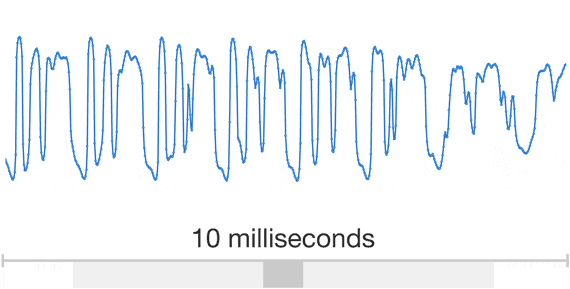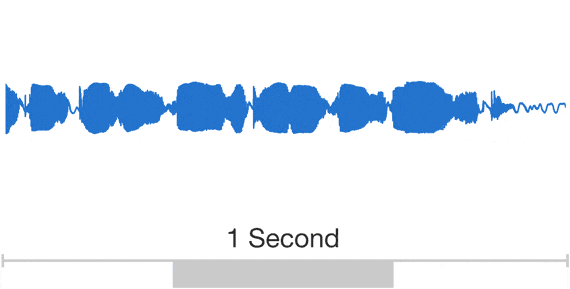
Audio exhibits patterns at multiple time scales. Source: Google DeepMind https://deepmind.com/blog/wavenet-generative-model-raw-audio/
By carefully analyzing the shortcomings of unsuccessful models and identifying the root causes of their underperformance, researchers and practitioners can gain invaluable insights into the intricacies of TTS model training. These lessons can then inform and refine the training process, leading to more robust and high-performing models. In this article, we embark on a comprehensive journey, exploring the intricate world of TTS models.
How it all started?
At Peech, we’re dedicated to making Text to Speech accessible to everyone — individuals and publishers alike. Our innovative technology converts web articles, e-books, and any written content into engaging audiobooks. This is beneficial for anyone who prefers listening to reading and, especially, individuals with dyslexia, ADHD, or vision impairments. The heart of our app lies in its text-to-speech technology. I’ve recently joined the impressive startup’s team with the ambition of advancing our capabilities in AI and Machine Learning. To achieve this, we’ve embarked on a research journey focused on training models in this domain.
I’m excited to share with you the results I’ve achieved in our research and model training. However, let’s go through some theory at first.
One-to-Many Mapping Problem in TTS
In TTS, the goal is to generate a speech waveform y from a given input text x. This can be represented as a mapping function f such that: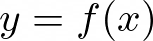
However, the mapping from text to speech is not unique, as there can be multiple valid speech outputs y for the same input text x. This is because speech is a complex signal that encodes various types of information beyond just the phonetic content, such as pitch, duration, speaker characteristics, prosody, emotion, and more. Let’s denote these additional factors as a set of variation parameters v. Then, the mapping function f can be rewritten as: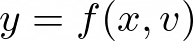
This means that for a given input text x, the speech output y can vary depending on the values of the variation parameters v. For example, consider the input text x = “Hello, how are you?”. Depending on the variation parameters v, we can have different speech outputs: - If v represents pitch contour, we can have a speech output with a rising pitch at the end (questioning tone) or a falling pitch (statement tone). - If v represents speaker identity, we can have speech outputs from different speakers, each with their unique voice characteristics. - If v represents emotion, we can have speech outputs conveying different emotions, such as happiness, sadness, or anger. Mathematically, we can represent the variation parameters v as a vector of different factors: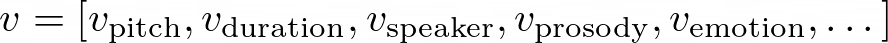
The challenge in TTS is to model the mapping function f in such a way that it can generate appropriate speech outputs y for a given input text x and variation parameters v. This is known as the one-to-many mapping problem, as there can be multiple valid speech outputs for the same input text, depending on the variation factors. There are two main approaches to modeling the specific aspects of the variation parameters v:
- Modeling Individual Factors: In this approach, each variation factor is modeled independently, without considering the interdependencies and interactions between different factors. For example, a model might focus solely on predicting pitch contours or duration values, treating them as separate components. While this approach can capture specific aspects of the variation parameters, it fails to model the variation information in a comprehensive and systematic way. The interdependencies between different factors, such as the relationship between pitch and prosody or the influence of speaker characteristics on duration, are not accounted for.
- Unified Frameworks for Modeling Multiple Factors: Recent research has proposed unified frameworks that aim to model multiple variation factors simultaneously, capturing their complementary nature and enabling more expressive and faithful speech synthesis. In this approach, the TTS model is designed to jointly model and generate multiple variation factors, considering their interdependencies and interactions. For instance, a unified framework might incorporate modules for predicting pitch, duration, and speaker characteristics simultaneously, while also accounting for their mutual influences. Mathematically, this can be represented as a mapping function f that takes the input text x and generates the speech output y by considering the combined effect of multiple variation parameters v:
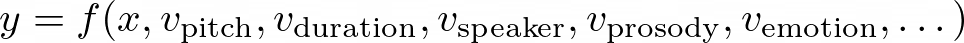
By modeling the variation parameters in a unified and comprehensive manner, these frameworks aim to capture the complex relationships between different factors, enabling more expressive and faithful speech synthesis that better reflects the nuances and variations present in natural speech. The unified approach to modeling variation parameters in TTS systems has gained traction in recent years, as it addresses the limitations of modeling individual factors independently and enables the generation of more natural and expressive speech outputs.
AR and NAR
Globally, TTS models can be categorized as either autoregressive or non-autoregressive, and in the following chapters, we will review these two paradigms in depth, paving the way for a comprehensive understanding of the state-of-the-art in text-to-speech synthesis.
Next chapter
Part 2: Autoregressive models world 🌍 Author: Nick Ovchinnikov
Original article: https://medium.com/@peechapp/text-to-speech-models-part-1-intro-little-theory-and-math-0ffa5d3e0e3f
Level up your reading with Peech
Boost your productivity and absorb knowledge faster than ever.
Start now