Autoregressive Models World
Tue Jun 11 2024 • Andrey Paznyak

Read the Full Series of ML TTS exploration
- Part 1: Intro, Little Theory and Math 📘
- 👉Part 2: Autoregressive models world 🌍
- Part 3: Non-autoregressive models hideout 🕵️♂️
- Part 4: Autoregressive and hybrid models review 📊
- Part 5: Non-autoregressive models review📝
- Part 6: DelightfulTTS implementation and training 🛠️
Any structured data can be transformed into a sequence. For instance, speech can be represented as a sequence of waveforms. Neural sequence generation methods can be used to generate such sequences, and there are two main categories of models for this purpose: autoregressive (AR) and non-autoregressive (non-AR) sequence generation methods. I believe, that any sequence can be generated using neural sequence generation methods (but not sure).
Autoregressive models
Autoregressive (AR) sequence generation involves generating a sequence one token at a time in an autoregressive manner. In an AR model, the current value in the sequence is predicted based on the previous values and an error term (often referred to as white noise, which represents the unpredictable or random component). The definition from wikipedia: autoregressive model:
In statistics, econometrics, and signal processing, an autoregressive (AR) model is a representation of a type of random process; as such, it is used to describe certain time-varying processes in nature, economics, behavior, etc. The autoregressive model specifies that the output variable depends linearly on its own previous values and on a stochastic term (an imperfectly predictable term); thus the model is in the form of a stochastic difference equation (or recurrence relation) which should not be confused with a differential equation.
The AR model’s ability to capture sequential dependencies allows it to generate speech with natural-sounding variations, for example — making it expressive. This is because the model can learn to predict the next value in the sequence based on the context provided by the previous values.
Autoregressive model definition
Probabilistic Perspective
To define AR Sequence Generation in a probabilistic manner, we can use the chain rule to decompose the joint probability of the sequence into a product of conditional probabilities.
AR Sequence Generation in a probabilistic manner
Inference

Inference math
AR model schema
Note: oversimplified schema, shouldn’t be considered seriously. SOS — start of the sequence, EOS — end of the sequence.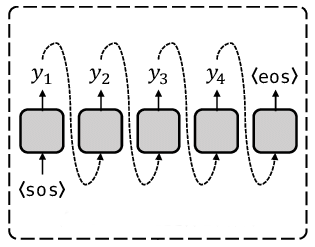
AR Schema
The best example of the AR world: Transformer & LLM
Transformers, which are the backbone of many state-of-the-art natural language processing (NLP) and speech models, including Large Language Models (LLMs), use a mechanism called self-attention to model relationships between all pairs of tokens in a sequence. Self-attention allows the model to capture long-range dependencies and weigh the importance of each token relative to others, enabling it to focus on the most relevant tokens when generating the next token. The attention mechanism in Transformers can be thought of as a weighted sum of the input tokens, where the weights represent the importance or relevance of each token for the current prediction. This allows the model to selectively focus on the most relevant tokens when generating the output. Mathematically, the attention mechanism can be represented as QKV attention: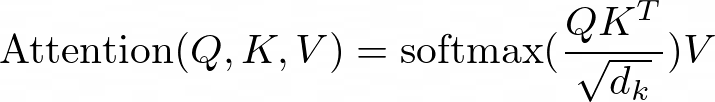
QKV attention
where:
- Q (Query) represents the current token or context for which we want to find relevant information.
- K (Key) and V (Value) represent the input tokens and their corresponding values or representations.
- dₖ is the dimensionality of the key vectors, and the scaling factor √dₖ is used for numerical stability.
- The softmax function is applied to the scaled dot-product of the query and key vectors, resulting in a set of weights that sum to 1. These weights determine the relative importance of each input token for the current prediction.
- The weighted sum of the value vectors, V, is then computed using the attention weights, producing the final output of the attention mechanism.
QKV attention
The self-attention mechanism in Transformers allows the model to capture dependencies between tokens in a sequence, regardless of their position or distance. This has made Transformers highly effective for various natural language processing tasks, including language modeling, machine translation, and text generation.
Cons of Autoregressive (AR) models
While the autoregressive nature of AR models allows them to capture sequential dependencies and generate expressive sequences, it also introduces a significant drawback: slow inference time, especially for long sequences.
Time Complexity Analysis

The time complexity of an algorithm or model refers to how the computational time required for execution scales with the input size. In the case of AR models, the input size is the sequence length, denoted as n. During inference, AR models generate sequences one token at a time, using the previously generated tokens to predict the next token. This sequential generation process means that the model needs to process each token in the sequence, resulting in a time complexity of O(n). In other words, the inference time grows linearly with the sequence length. This linear time complexity can become a significant bottleneck in real-time scenarios or when dealing with long sequences, such as generating long texts, speech utterances, or high-resolution images. Even with modern hardware and parallelization techniques, the sequential nature of AR models can make them computationally expensive and slow for certain applications. The slow inference time of AR models can be particularly problematic in the following scenarios:
- Real-time speech synthesis: In applications like virtual assistants or text-to-speech systems, the ability to generate speech in real-time is crucial for a seamless user experience. AR models may struggle to keep up with the required speed, leading to noticeable delays or latency.
- Long-form text generation: When generating long texts, such as articles, stories, or reports, the inference time of AR models can become prohibitively slow, making them impractical for certain use cases.
While AR models excel at capturing sequential dependencies and generating expressive sequences, their slow inference time can be a significant limitation in certain applications, especially those requiring real-time or low-latency performance or involving long sequences. One of the inherent challenges in autoregressive (AR) models is the unavoidable loss of quality for longer sequences. This issue is visually represented in the following plot: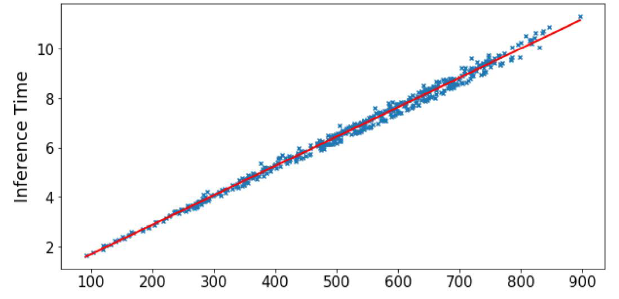
The dispersion of predicted values increases
As you can see, the dispersion or spread of the predicted values increases as the sequence length grows. This phenomenon occurs by design in AR models, and it’s crucial to understand the underlying reasons behind it.
Harmful Biases in Autoregressive (AR) Generation

Autoregressive (AR) models are prone to several harmful biases that can negatively impact their performance and the quality of the generated sequences. These biases can arise from various factors, including the training process, the model architecture, and the nature of the data itself. Let’s explore the reasons behind these, why do we have such kind of troubles?
Error Propagation
Error propagation occurs when errors in the predicted tokens accumulate and affect the subsequent tokens, leading to a compounding effect, where the errors in the early tokens propagate to the later tokens. This can cause the generated sequence to deviate significantly from the true sequence, especially for longer sequences.
The second term, represents the accumulated error propagation term, which grows as the sequence length increases.
Error-propagation term:
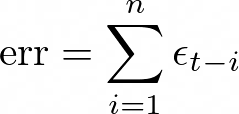
The worst-case scenario occurs when the error happens on the first token in the sequence, x̂₁. In this case, the error propagates and accumulates through the entire sequence, leading to the maximum deviation from the true sequence. In the context of text-to-speech synthesis, error propagation can lead to the generation of random noise or artifacts in the synthesized audio, making it difficult to avoid and potentially resulting in an unnatural or distorted output.
Label Bias
Label bias occurs when the normalization constraint over the vocabulary items at each decoding step in AR models leads to learning miscalibrated distributions over tokens and sequences. This can happen because the model is forced to assign probabilities that sum to 1 over the entire vocabulary, even if some tokens or sequences are highly unlikely or impossible in the given context. Mathematically, the probability distribution over the vocabulary items at time step t is typically computed using a softmax function: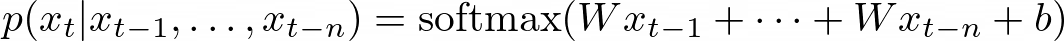
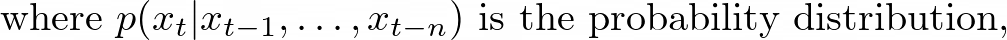
W is the weight matrix, and b is the bias term. This normalization constraint can lead to a bias towards certain tokens or sequences, even if they are unlikely or irrelevant in the given context. For example, consider a language model trained on a corpus of news articles. If the model encounters a rare or unseen word during inference, it may still assign a non-zero probability to that word due to the normalization constraint, even though the word is highly unlikely in the context of news articles. The consequences of label bias can be significant, especially in cases where the data distribution is highly skewed or contains rare or unseen events. It can lead to the generation of nonsensical or irrelevant tokens, which can degrade the overall quality and coherence of the generated sequences. This bias can be particularly problematic in applications such as machine translation, text summarization, or dialogue systems, where accurate and context-appropriate generation is crucial.
Order Bias
Order bias occurs when the left-to-right generation order imposed by AR models is not the most natural or optimal order for the given task or data. In some cases, the data may prefer a different generation order or require considering the entire context simultaneously, rather than generating tokens sequentially. For example, in text-to-speech synthesis, the natural flow of speech may not follow a strict left-to-right order. The pitch, intonation, or emphasis of a sentence can be determined by the context of the entire sentence, rather than the individual words. If the model is trained to generate the audio sequence in a left-to-right order, it may fail to capture these nuances, leading to an unnatural or strange-sounding output. That’s it for now, in the next article I will elaborate a bit regarding non-AR models.
Next chapter
Part 3: Non-autoregressive models hideout 🕵️♂️ Author: Nick Ovchinnikov
Original article: https://medium.com/@peechapp/text-to-speech-models-part-2-autoregressive-models-world-636d8aa0932d
Level up your reading with Peech
Boost your productivity and absorb knowledge faster than ever.
Start now